 mni Models
mni ModelsReleased on April, 2026
ByteDance Seed · * Equal contribution · † Corresponding authors
We present mni, a unified multimodal model natively trained on diverse
modalities, including text, images, videos, 3D geometry, and hidden representations.
We find that such training enables Context Unrolling, where the model explicitly reasons
across multiple modal representations before producing predictions. This process enables the model to
aggregate complementary information across heterogeneous modalities, facilitating a more faithful
approximation of the shared multimodal knowledge manifold and improving downstream reasoning fidelity.
As a result, mni achieves strong performance on both multimodal generation
and understanding benchmarks, while demonstrating advanced multimodal reasoning capabilities,
including in-context generation of text, image, video, and 3D geometry.
A model natively trained across diverse modalities develops the ability to unroll its internal reasoning across heterogeneous modal representations before producing outputs. Each modality becomes an atomic primitive — composable, invocable, and writable back into a shared context.
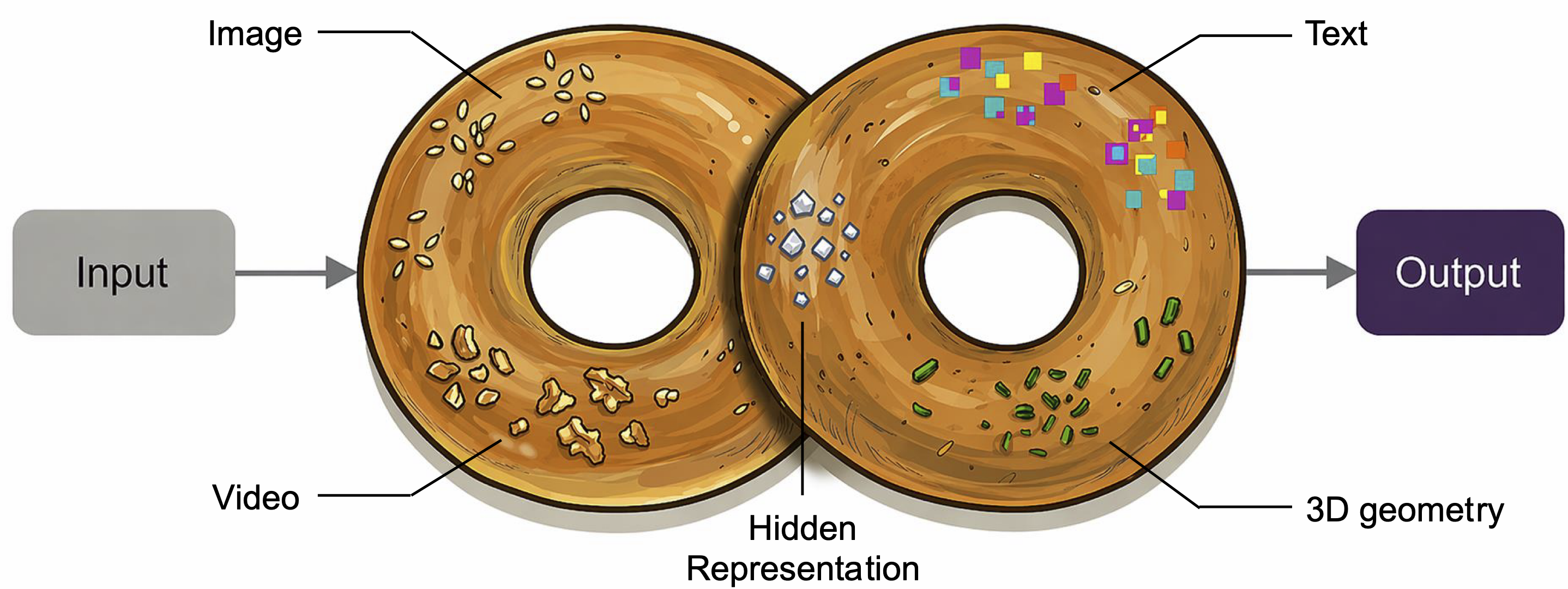 mni. Given an arbitrary task, mni selectively activates task-relevant contexts from a heterogeneous context pool—spanning text, image, video, 3D geometry, and beyond—into a shared workspace before producing predictions. This mechanism enables the model to aggregate complementary information across modalities, improving downstream reasoning and generation fidelity.
mni. Given an arbitrary task, mni selectively activates task-relevant contexts from a heterogeneous context pool—spanning text, image, video, 3D geometry, and beyond—into a shared workspace before producing predictions. This mechanism enables the model to aggregate complementary information across modalities, improving downstream reasoning and generation fidelity.
Context unrolling in visual understanding primarily occurs through CoT-style textual rollout, which enriches the latent workspace with finer semantic decompositions before producing the final answer. Text thinking context yields consistent gains across perception, reasoning, document, and spatial understanding benchmarks.
Understanding with Text-Thinking. Validated on downsampled mutiple benchmarks. Text thinking context improves performance consistently across all evaluated dimensions.
| Context | BLINK ↑ | MMStar ↑ | MMBench-V11 ↑ | SimpleVQA ↑ | AI2D ↑ | Chartqa ↑ | Docvqa ↑ | HallusionBench ↑ | Erqa ↑ | MMSI ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| baseline | 60.8 | 59.4 | 76.2 | 50.4 | 90.2 | 85.5 | 93.5 | 69.6 | 41.5 | 31.5 |
| + text thinking | 61.6 | 66.5 | 77.1 | 51.4 | 92.3 | 88.0 | 94.0 | 71.3 | 44.5 | 32.6 |
Visual generation benefits from multi-granularity context, reducing the inherent ambiguity of mapping language to images. Before synthesizing an image, mni can (i) roll out fine-grained textual specifications — attributes, counts, spatial constraints — via text thinking, and/or (ii) unroll visual context representations carrying strong structural information. Longer textual context consistently improves both aggregate and high-atomicity performance; combining text thinking with visual token unrolling yields the most consistent gains, confirming that textual and visual contexts are complementary.
Text-to-Image Generation Ablation. GenEval-2 (TIFAGM) and per-attribute breakdown. Higher is better.
| Context | TIFAGM | Object | Attr. | Count | Pos. | Verb | Overall |
|---|---|---|---|---|---|---|---|
| baseline | 29.25 | 91.64 | 90.00 | 52.03 | 77.67 | 26.25 | 0.56 |
| + short text | 37.35 | 93.18 | 92.45 | 60.14 | 76.92 | 38.83 | 0.59 |
| + long text | 43.94 | 91.86 | 91.13 | 67.03 | 77.03 | 38.31 | 0.61 |
| + visual unrolling | 48.02 | 94.42 | 92.96 | 66.92 | 79.28 | 53.96 | 0.61 |
| + short text & visual unrolling | 49.16 | 93.13 | 92.68 | 68.36 | 76.83 | 43.34 | 0.64 |
| + long text & visual unrolling | 53.44 | 92.34 | 92.32 | 72.98 | 80.23 | 42.81 | 0.66 |
| + oracle & visual unrolling | 57.21 | 94.77 | 97.89 | 69.47 | 90.64 | 56.00 | 0.73 |
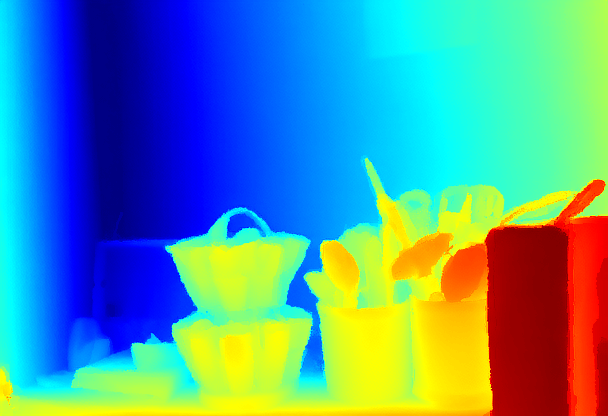
Context unrolling also benefits monocular depth estimation. A depth-related caption describes the scene's structural layout (textual context) recovers key geometric features; combining it with unrolled visual context further corrects residual ambiguities, yielding sharper depth boundaries and globally consistent depth maps.
Depth Estimation Ablation. δ₁ ↑ higher is better; AbsRel ↓ lower is better. Evaluated on NYU-Depth v2.
| Metric | baseline | text context | visual context |
|---|---|---|---|
| δ₁ ↑ | 83.21% | 83.27% | 84.01% |
| AbsRel ↓ | 0.2028 | 0.2029 | 0.1970 |
Spatial understanding requires resolving geometric ambiguities — viewpoint changes, foreshortening, and occlusions — that freeform text reasoning alone cannot handle. mni incorporates camera pose estimation and novel-view synthesis as atomic primitives: camera pose provides geometry-grounded textual context, while synthesized views enable visual imagination as context. Both substantially improve spatial reasoning on MMSI-Bench compared to text chain-of-thought alone.
Spatial Understanding Evaluation. Textual contexts denote geometry-grounded text (e.g., camera pose estimation results). Visual contexts refer to novel-view synthesis results used as context. Evaluated on a downsampled MMSI-Bench.
| Context | Overall | Positional Relationship |
|---|---|---|
| baseline | 27.14 | 19.63 |
| + text thinking | 28.15 | 30.25 |
| + text geometric contexts | 30.15 | 33.95 |
| + visual geometric contexts | 34.17 | 35.80 |
State-of-the-art results across understanding, generation, and geometry benchmarks — from a single unified model with only 3B activated parameters.
Multimodal Understanding. Compared against models with similar MoE architecture and activation scale (no thinking). Bold = best in column.
| Benchmark | Qwen3-VL-30B-A3B | InternVL3.5-30B-A3B | mni |
|---|---|---|---|
| BLINK | 67.7 | 60.4 | 63.0 |
| MMStar | 78.4 | 72.0 | 63.8 |
| MMBench-v11 | 78.4 | 84.8 | 75.3 |
| VlmsAreBlind | 67.5 | — | 76.4 |
| SimpleVQA | 52.7 | — | 53.3 |
| RealWorldQA | 73.7 | 72.3 | 76.0 |
| Textvqa | — | 80.5 | 81.0 |
| AI2D | 85.0 | 86.8 | 91.5 |
| Chartqa | 86.8 | 87.4 | 86.9 |
| Docvqa | 95.0 | 94.2 | 92.8 |
| HallusionBench | 61.5 | 53.8 | 70.1 |
| MuirBench | 73.0 | 53.1 | 64.2 |
| Erqa | 51.3 | 41.5 | 45.0 |
| MMSI-Bench | 30.3 | 27.5 | 31.5 |
| MVBench | 72.3 | 72.1 | 68.4 |
| Video-MME | 74.5 | 68.7 | 67.2 |
Text-to-Image Generation. GenEval2 measures compositional accuracy; DPG measures dense prompt following; LongText measures long-form prompt following. Higher is better.
| Model | GenEval2 ↑ | DPG ↑ | LongText-EN ↑ | LongText-CN ↑ | Inhouse ↑ |
|---|---|---|---|---|---|
| Qwen-Image | 30.67 | 88.32 | 94.3 | 94.6 | 55.16 |
| Z-Image | 41.83 | 88.14 | 93.5 | 93.6 | 55.19 |
| Flux | 34.59 | 83.84 | 60.7 | - | 49.91 |
| mni |
54.12 | 88.55 | 97.5 | 96.8 | 63.87 |
Image Editing — GEdit-Bench EN (Full set). G_SC = semantic correctness; G_PQ = perceptual quality; G_O = overall. Higher is better.
| Model | G_SC ↑ | G_PQ ↑ | G_O ↑ |
|---|---|---|---|
| Flux-Kontext-dev | 7.16 | 7.37 | 6.51 |
| Step1X-Edit v1.1 | 7.66 | 7.35 | 6.97 |
| Step1X-Edit v1.2 | 7.77 | 7.65 | 7.24 |
| Emu-3.5 | 8.11 | 7.70 | 7.59 |
| Z-Image-Edit | 8.11 | 7.72 | 7.57 |
| Qwen-Image-Edit | 8.15 | 7.86 | 7.54 |
| mni |
8.42 | 7.85 | 7.75 |
Text-to-Video Generation — VBench 1.0. Total Score combines Quality Score and Semantic Score. Higher is better.
| Model | Total Score ↑ | Quality Score ↑ | Semantic Score ↑ |
|---|---|---|---|
| Wan2.1 | 85.59 | 83.43 | 76.11 |
| Hunyuan Video | 83.69 | 83.35 | 76.88 |
| mni |
85.07 | 84.29 | 83.11 |
Video Editing — FiVE Benchmark. Evaluated across structure preservation, background fidelity, text alignment, motion quality, and instruction-following (FiVE score). Higher is better except Dist.↓ and LPIPS↓.
| Method | Structure | Background Preservation | Text Alignment | Motion | FiVE ↑ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dist.×10³ ↓ | PSNR ↑ | LPIPS×10² ↓ | SSIM×10² ↑ | CLIPS ↑ | CLIPSedit ↑ | Fid.S.×10² ↑ | YN ↑ | MC ↑ | ∪ ↑ | ∩ ↑ | Acc ↑ | |
| TokenFlow | 35.62 | 19.06 | 263.61 | 72.51 | 26.46 | 21.15 | 89.00 | 19.36 | 35.51 | 36.68 | 18.18 | 27.43 |
| DMT | 85.95 | 14.71 | 404.60 | 51.64 | 26.66 | 21.44 | 82.30 | 34.78 | 62.06 | 62.98 | 33.86 | 48.42 |
| Vid2Me | 22.37 | 21.15 | 263.91 | 70.69 | 26.84 | 21.05 | 90.06 | 20.03 | 33.50 | 36.20 | 17.34 | 26.77 |
| AnyV2V | 71.36 | 15.90 | 348.59 | 50.77 | 24.89 | 19.72 | 60.36 | 30.62 | 45.42 | 48.96 | 27.09 | 38.02 |
| VideoGrain | 12.40 | 27.05 | 185.21 | 79.13 | 25.69 | 20.31 | 88.57 | 30.50 | 43.97 | 44.30 | 30.17 | 37.23 |
| Pyramid-Edit | 28.65 | 20.84 | 276.59 | 71.72 | 26.82 | 20.20 | 80.59 | 33.67 | 54.01 | 56.36 | 31.31 | 43.84 |
| Wan-Edit | 12.53 | 25.57 | 94.61 | 82.55 | 26.39 | 21.23 | 89.43 | 41.41 | 52.53 | 55.72 | 38.22 | 46.97 |
| mni |
42.96 | 20.30 | 245.18 | 67.00 | 27.32 | 21.47 | 83.37 | 69.67 | 86.15 | 88.50 | 67.23 | 78.03 |
Camera Pose Estimation on RealEstate10K and CO3Dv2
AUC@30↑ higher is better; RPE trans↓ and RPE rot↓ lower is better.
| Method | RealEstate10K | CO3Dv2 | ||||
|---|---|---|---|---|---|---|
| AUC@30 ↑ | RPE trans ↓ | RPE rot ↓ | AUC@30 ↑ | RPE trans ↓ | RPE rot ↓ | |
| Flare | 84.42 | 0.4215 | 0.0532 | 72.23 | 2.1242 | 0.0342 |
| Cut3r | 85.32 | 0.4023 | 0.0424 | 75.62 | 1.5321 | 0.0331 |
| VGGT | 88.23 | 0.3886 | 0.0386 | 86.23 | 1.1432 | 0.0285 |
| mni | 88.32 | 0.3766 | 0.0289 | 75.21 | 1.5955 | 0.0269 |
Monocular Depth Estimation
δ₁↑ higher is better; AbsRel↓ lower is better. Zero-shot evaluation across five standard benchmarks.
| Method | NYU | KITTI | SINTEL | ETH3D | DIODE | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | |
| Marigold | 92.75 | 0.0781 | 87.87 | 0.1108 | 62.24 | 0.4666 | 97.12 | 0.0564 | 81.64 | 0.2266 |
| Cut3r | 91.64 | 0.0824 | 86.42 | 0.1253 | 55.64 | 0.4723 | 95.34 | 0.0632 | 73.21 | 0.3521 |
| DA3 giant | 94.78 | 0.0579 | 93.96 | 0.0824 | 66.54 | 0.3821 | 98.79 | 0.0324 | 82.69 | 0.2050 |
| VGGT | 96.10 | 0.0499 | 94.29 | 0.0803 | 66.11 | 0.4551 | 98.35 | 0.0326 | 82.15 | 0.2115 |
| mni | 96.22 | 0.0542 | 96.92 | 0.0621 | 74.27 | 0.3340 | 98.91 | 0.0312 | 83.83 | 0.2034 |
mni Can Domni generates images from complex textural prompts and performs precise instruction-following edits. The model can also estimate depth from a single image and synthesize novel views from arbitrary camera poses.















<campose>tx ty tz rx ry rz</campose> <fov>fovh</fov><fov>fovw</fov>
— the six values give the translation and rotation of the next view relative to the current one, fovh and fovw are field of views in the vertical and horizontal directions.
The entire instruct, including all camera pose and FOV values, is encoded purely by the language tokenizer with no separate geometric encoder.
Hover over each image to see the full instruct prompt used to generate the next view.








mni handles diverse video generation tasks in a single unified model: generating from text prompts or reference images, composing specified subjects into new scenes, and applying instruction-based edits — all with high temporal consistency.

mni predicts the next first-person or third-person views from discrete action text inputs — no separate policy network required. Trained on diverse video navigation data, the model develops precise action control and internalizes fundamental physical laws: objects carry inertia, characters obey gravity, and solid boundaries enforce collision constraints. These behaviors emerge naturally from unified multimodal training rather than explicit physics simulation.
WASDCamera movement ↑↓←→View rotation SpaceJump